Tech Blog: Designing Data Service APIs for Science Gateways with GraphQL
- Details
- Published on Tuesday, 17 April 2018 12:00
By Steven Snyder
Explanation of GraphQL
GraphQL is a Query Language representing an alternative to REST for data interfaces that is particularly suited to new and evolving systems. As “graph” indicates, and as its provenance at Facebook implies, GraphQL is particularly suited to queries on network data like social graphs.
What are the benefits to science gateway developers? What problems does it address?
If it’s ever occurred to you that it’d be easier to accomplish what you want with a data service if you could just write SQL for what you need, or, conversely, if you have worked in the data tier and wondered if you’ll ever be finished writing in queries to satisfy all the needs of the presentation layer(s), GraphQL may be of interest.
The work to support GraphQL in the data layer can be minimal. It specifies which entities it knows about, which parameters are available to select them, and it specifies the relationships between entities. The client then is left to decide how to approach access to the schema, using the grammar of types and their connections to specify traversals. So, it’s sort of a white-list partial version of SQL over those covered data.
You’ll see example queries later that assemble these small building blocks in the data definition into queries that would require many HTTP requests in a similarly-specified REST interface, and which would further require client logic to error-guard and to stitch all the responses back into a representative document. This makes it a compelling trade-off in that respect: for a relatively small effort to construct a query in the GraphQL syntax, you can get the data in the particular format you need in one shot.
Even simpler than constructing a GraphQL query would be for a REST endpoint to return exactly the required data, then the client would only need the URL and could forego query construction. However, this isn’t always practical, as it requires the server to know ahead of time exactly what is required of the data presentation. Particularly when a service is in flux because it’s under development, GraphQL shines as a way to reduce blocking of client development waiting for support for new queries from the data layer.
It also helps to avoid API bloat: mobile apps, web portals, statistics and auditing engines, and other diverse clients have different interests in the data, and precisely-defined REST endpoints supporting each can accumulate, complicating documentation and maintenance.
What would make someone choose this solution over another?
The main alternative to GraphQL for read-only queries is to implement a REST service, though for mutations it shares more with operation-oriented solutions like XML-RPC and SOAP. Since this document focuses on data consumers, I’ll use REST as the basis for comparison.
Science work deals with social graphs like any other field, seeking to forge new connections over similar interests and expertise, so a query language designed with that in mind is particularly suitable. GraphQL is generally applicable as well, as you can think of any relational data as composing small networks, with foreign keys representing edges. GraphQL and REST can model all the same things; the difference is in the approach.
The main difference in that approach is that GraphQL assigns more flexibility and expressiveness to clients where REST provides a more curated and specific interface. Neither approach is flatly superior, and the aim of this document is to highlight some of the trade-offs.
Steps of implementation part one—Sample Data:
A concrete example of how GraphQL works might be useful to see how or if it fits into your service. For simplicity, I’ll use some decidedly un-scientific data to demonstrate, but I’ll try to tie it back into some hypothetical science gateway usage later.
Full code is available in this git repository, should you want to experiment further.
The model looks like this:
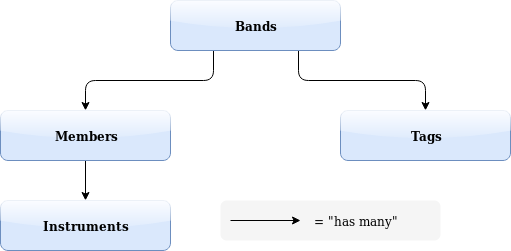
For each node, we have a text “name” field, and we have purely relational tables representing the has-many relationships. An example query to get a list of instrument proficiencies for the members of a given band might be:
SELECT DISTINCT imr.instrument FROM band_member_rel bmr WHERE band = ‘The Smiths’ LEFT JOIN instrument_member_rel imr ON imr.member = bmr.member;
Steps of implementation part two—Bare-Bones Service:
Per tradition, to begin our GraphQL interface to this data, we’ll set up “Hello world!” to figure out what boilerplate is required of us, and build up the application around that
We’ll be using the reference implementation of GraphQL in JavaScript, though there are several other implementations.
There are two major parts of the GraphQL implementation, the schema definition describing what data are available, and the “root object” containing the mechanism to access them.
For “Hello, World!”, our schema.js:
// utility to parse schema string
const { buildSchema } = require('graphql');
module.exports = buildSchema(`
"Global"
type Query {
"Greeting"
hello: String!
}
`);
We define a type “Query” and indicate that it has a string property “hello”. The exclamation point signifies that this value cannot be null. The quoted strings above each definition are optional bits of context that are parsed as markdown and put into the auto-generated API documentation.
Now, we need to set up a root object that knows how to fulfill the contract of supplying a not-null string in response to a request for the “hello” field of Query (definitions.js):
module.exports = {
'hello': () => 'Hello world!'
};
This is the simplest type of “resolver”, a static context-free function.
We link these two parts of the API together when instantiating our GraphQL server. There’s a convenient express-graphql middleware for doing so (server.js):
const express = require('express'), app = express();
const graphqlHTTP = require('express-graphql');
const port = process.env.NODE_PORT || 8888;
app.use('/api', graphqlHTTP({
'schema': require('./graphql/schema'),
'rootValue’: require('./graphql/definitions'),
'graphiql': true
}));
app.listen(port, () => console.log(`:${port}`));
The third bit of configuration, “‘graphiql’: true”, enables a useful development tool at the specified URL. This is what it looks like after `npm start`-ing the server:

From left to right:
-
an editable area to enter a query
-
the results of that query (after pressing the “play” button above)
-
schema documentation, including the types we defined and documentation markdown.
One more example with GraphIQL before moving adding the data:

It’s not important to understand this query, but it shows a few things:
-
The “shape” of the response matches the “shape” of the query. “{ hello }” gets “{ hello }”, “{ __schema { queryType { … } }” gets “{ __schema { queryType { … } }”. This results in intuitive client code because you essentially have a prototype of the response written into the request. Also, it means you’re getting no more and no less than you ask for.
-
GraphQL provides schema introspection. This is how that documentation pane is generated. This can be leveraged for further documentation or in automated testing to ensure the quality of the service.
Steps of implementation part three—Filling Out the Schema:
Back to the sample data, let’s add access to the full list of bands.
schema.js
module.exports = buildSchema(`
type Query {
bands: [Band!]!
}
type Band {
name: String!
}
`);
We add a type representing a band, which just has the one field for now, and change the resolvers available through the global Query to return a list of them (again, regarding the exclamation points, the list cannot be null, and the inner mark indicates that it also cannot contain nulls).
Then, definitions.js must access our database when called on to resolve for “bands”:
module.exports = require('../db').then((dbh) => {
return {
'bands': () => dbh.all('SELECT name FROM bands')
};
});
The formatting of this file changed a bit to support the database file returning a promise that resolves to a handle when the database is ready, but the main action is in the return value, our root object.
Running the server again, we can verify the query works. I’ll use a command line utility available in the git repo to issue queries rather than GraphIQL screenshots going forward:
$ node client '{ bands { name } }'
{
"data": {
"bands": [
{ "name": "Electronic" },
{ "name": "The Smiths" },
{ "name": "Freebass" }, … more
]
}
}
Note as well that I have to ask for the fields I want specifically, there’s no default representation of a band:
$ node client '{ bands }'
{
"errors": [
{
"message": "Field \"bands\" of type \"[Band!]!\" must have a selection of subfields. Did you mean \"bands { ... }\"?", … more
We could add lists of the other node types in exactly the same way, but let’s delay that and instead add some depth to the query, so we can see the bands’ members.
The schema.js changes are unsurprising. We define a new type for Member like we did for Band, and we indicate that has-many relationship by stating each Band has an array of Members:
module.exports = buildSchema(`
type Query {
bands: [Band!]!
}
type Band {
name: String!
members: [Member!]!
}
type Member {
name: String!
}
`);
There are several ways to consider how to implement “deep” resolvers. We could, for example, always select the members of a band in a JOIN, rendering the above definitions essentially the same. In the context where GraphQL originally came up for my science gateway work, we were dealing with a document store database for which this approach made a lot of sense. It’s often practical for relational databases as well. Like an object-relational model aerating all the properties of a model, even those we don’t use, there’s often no noticeable performance impact.
Here, though, we’ll implement a general approach where we return an object from the root, and object resolves its subfields in method that are called as-needed. This has the advantage of letting us chain subqueries together to arbitrary depth:
definitions.js
class Band {
// bind database handle and parameters
constructor(dbh, { name }) {
this.dbh = dbh;
this.name = name;
}
static list(dbh) {
return dbh.all('SELECT name FROM bands')
// return instances of Band rather than "raw" representations of the database rows
.then((rows) => rows.map((fields) => new Band(dbh, fields)))
}
// resolve subfield
get members() {
return this.dbh.all('SELECT member AS name FROM band_member_rel WHERE band = ?', [ this.name ]);
// (TODO: instantiate Member objects from rows as well, so query chaining can continue)
}
}
module.exports = require('../db').then((dbh) => {
return {
'bands': () => Band.list(dbh)
};
});
A test query:
$ node client '{ bands { name members { name } } }'
{
"data": {
"bands": [
{
"name": "Electronic",
"members": [
{ "name": "Bernard Sumner" },
{ "name": "Johnny Marr" },
{ "name": "Chris Lowe" },
{ "name": "Neil Tennant" },
{ "name": "Karl Bartos" }
]
},
{
"name": "The Smiths",
"members": [
{ "name": "Morrissey" },
{ "name": "Johnny Marr" },
{ "name": "Andy Rourke" },
{ "name": "Mike Joyce" }
]
}, … more
Looks great, but you probably notice that this implementation suffers from “the N+1 query problem”. We do one query to get a list of things, and then N queries to get data about each, when we could have batched the whole lot as a join. We can do that with GraphQL, because it passes resolvers enough contextual information to figure out that they should take this approach. This is a somewhat complicated topic that’s addressed by projects like join-monster. We’ll bracket the issue for the time to explore a simpler facet of query context: adding an argument to the bands field, so we can get information about a particular one rather than the entire list.
schema.js
Change the line representing the global resolver for bands:
type Query {
bands(name: String): [Band!]!
}
(No exclamation point on String here to make the parameter optional)
definitions.js
Change the list() method to filter on the name when present, and change the root object to pass along the arguments supplied to it by the GraphQL mechanism:
class Band {
// ...
static list(dbh, { name }) {
const params = [];
let where = '';
if (name) {
where = 'WHERE name = ?';
params.push(name);
}
return dbh.all(`SELECT name FROM bands ${where}`, params)
// return instances of Band rather than "raw" representations of the database rows
.then((rows) => rows.map((fields) => new Band(dbh, fields)))
}
// ...
}
module.exports = require('../db').then((dbh) => {
return {
'bands': (args, info) => Band.list(dbh, args)
};
});
This works as expected:
$ node client '{ bands(name: "Joy Division") { members { name } } }'
{
"data": {
"bands": [
{
"members": [
{ "name": "Ian Curtis” },
{ "name": "Peter Hook" },
{ "name": "Stephen Morris" }
]
}
]
}
}
The (unused) parameter “info” in the root object contains the rest of the context of the query, including its parsed tree.
Since all of our data has the same “name” property, and all of it interrelates in the same way, API support for listing the other types and following their edges plays out in exactly the same way, using the same code while parameterizing the table and column names. Having done that, let’s skip ahead to look at some of the types of queries we can support.
How can it/has it been implemented by SGCI staff?
The best way to think about how GraphQL could be harnessed for your purposes might be to look at some queries and think about whether they are analogous to any questions you might want answered about your data. Or rather, if they approach to queries is appropriate for your data. Are there exploratory aspects to your user experience? What portion of your queries do you know right now versus those that you hope to suss out over time? Is there really one true portal for the data, or are there also apps and independent researchers?
Our sample data is trivial enough that we have to stretch a bit to find interesting queries for it, but it hints at how the possibilities open up with real, complexly-related data. Some examples:
“What other bands are associated with members of New Order?” – this is an example of the general question of which materials are related to another, useful for any user experience that hopes to enable new connections:
$ node client '{ bands(name: "New Order") { members { name bands { name } } } }'
{
"data": {
"bands": [
{
"members": [
{
"name": "Bernard Sumner",
"bands": [
{ "name": "Electronic” },
{ "name": "New Order" }
]
},
{
"name": "Peter Hook",
"bands": [
{ "name": "Freebass” },
{ "name": "New Order" },
{ "name": "Joy Division" }
]
},
{
"name": "Stephen Morris",
"bands": [
{ "name": "New Order" },
{ "name": "Joy Division" }
]
}
]
}
]
}
}
Following the prior query a step further, we get the members of those bands, a friend-of-a-friend query. This type of query can be useful to connect networks by finding indirect relationships between entities, and then suggesting more direct ones. (“You both worked on projects related to X, and there’s grant money available to study X next year...”)
{
bands(name: "New Order") {
members {
name
bands {
members {
name
}
}
}
}
}
Expertise matching: say you’re starting a new “post-punk” band (as you ought to) and you need to find someone with vocal talent in that context. Or, you’re starting a new science gateway and you need to find a collaborator with a background in biotech to help your curate that section.
{
tags(name: "post-punk") {
bands {
members(instrument: "vocals") {
name
}
}
}
}
To step outside the example schema and think for a bit about a non-social-graph-oriented query, in a hypothetical schema representing a material science hub, one might try to find out which public organizations have programs involving research of aluminum by following simulation tool parameters to the tools’ authors:
{
materials(el: "Al") {
tools {
authors {
organization(type: "public")
}
}
}
}
Again, imagine how these queries would play out in a REST interface. Most would involve many round trips and document-stitching to get a useful result unless there was a very specifically-oriented endpoint. And if there was, even minor changes to the traversal would complicate matters again.
Additional Resources:
If you are interested, of course, check out the official documentation and have a look through Awesome GraphQL to get an idea of what’s going on in the community surrounding GraphQL.
Tech Blogs are written by SGCI experts and offer a variety of resources for gateway builders and developers. It's likely that, from reading this post, you'll have what you need to incorporate these technologies on your own, but we're here to help if you ever need it. Submit a Consulting Services Request Form to get help with adding this or any other tool, or email us at help@sciencegateways.org with questions.
View all Tech Blogs here.