Back Tech Blog: Benefits of Application Programming Interfaces (APIs)
- Details
- Published on Tuesday, 31 July 2018 16:00
By Josue Balandrano Coronel
What are APIs?
In software development, Application Programming Interfaces (APIs) are a key part which enables sharing and extending functionality implemented by other developers. An API can be defined as a public contract between author and user which defines how to use a specific tool. In this definition, the author references any software developer who writes a specific library, framework, service, or any other software tool. A user is anyone who uses said library, framework or software tool to build any type of application. An API can be viewed as a public contract because the author defines how it must be used and what it will return without necessarily exposing how the functionality is implemented.
Why APIs?
The most popular computer languages are High Level Computer Languages (HLL), e.g. Javascript, Python, Go, Java, etc. These type of computer languages are considered high level because of the use of natural language. Meaning, everyday words are part of these languages. Being able to write code by using natural language makes it easier for software developers to understand, use, and share software. APIs share the same idea as High Level Computer Languages since they also define an abstraction layer closer to the natural language used in a specific context. With this abstraction idea in mind and the fact that APIs also present a contract describing how to use them, they become a key addition to any product.
One of the most powerful features of any library or service is the ability to be integrated with other applications. An API facilitates these types of integrations by defining public interfaces which can be easily used. The interfaces mentioned can be of different types. One way to use a library could be by using a class, static methods, or simply sending a message to a centralized message queue. Also, some APIs are based on services like Web Services. These APIs use a specific architecture referred to as Representational State Transfer (REST). We will dive into the different types of APIs in the next section.
Another powerful feature of APIs is the ability to be easily understood. This is done by leveraging natural language when defining public interfaces. By using natural language, the usage of an API becomes more natural and this also improves readability of the code that uses an API. This abstraction is a double-edged sword because it pushes the author of an API to plan the architecture with enough foresight that the API should not go through abrupt changes in the future. Knowing how an API will be used or how the needs of the users will change over time has proven to be a difficult task. There are different ways to avoid breaking the hard work of other users unknowingly but this is still one of the hardest aspects of building an API. We will go through some of the best practices when building APIs in the last section.
Types of APIs
There are different types of APIs, but they still share the same abstraction, reuse, and extensible principles. In this article, we will focus on four different types (Library, Remote, Hardware and Operating Systems) but we will dive deeper into Remote APIs (e.g. REST APIs).
To be clear, there are no official API categories and the categories described here are based out of the mere observation by the author.
Library APIs
Software libraries are powerful packages which usually focus on solving a specific problem. It is common to use stable and robust libraries to avoid doing extra work, introducing bugs and to expedite development. A library is used through an API. This is where we most see the abstraction layer and natural language an API leverages on. For instance, Python has a powerful standard library with different packages. We can use the shutil package to copy a file like so:
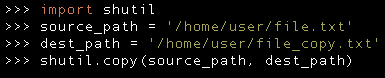
In this example, the actual implementation of the copy action is abstracted from us and the package exposes the copy function which improves readability and conveys what the specific line of code is doing without having to dive into the standard lib code.
The standard library example is simple. We have to remember every time we write a class or a function, and we expose some functionality publicly, we are creating an API, and we should take into consideration who and how this API is going to be used.
Hardware APIs
This category might be a bit confusing if we take into consideration that any piece of hardware already has an API defined to describe how can it be extended and used. This is usually called a specification. The type of API we are referring to here is of the software kind, although it is built specifically to manage a piece of hardware. These types of APIs deserve their own category because the natural language and abstraction context when one is dealing directly with a piece of hardware are different from the abstraction and natural language used when managing remote services or 3rd party libraries.
Hardware APIs are very powerful and allow us to directly manipulate things like an embedded board (e.g. Arduino, Raspberry PI, etc...), different pieces of a computer (e.g. Monitor, Network Card, etc...) and many other physical devices.
Operating System APIs
Operating System APIs also contain a very specific and unique set of abstraction layers and natural language. These APIs allow developers to build powerful applications tailored to specific operating systems, e.g. Desktop applications, native mobile applications, etc.
Remote APIs
Remote APIs refer to any API exposed by a remote service. In this day and age, we see more remote APIs than ever before. Mainly these APIs are built on top of the HyperText Transfer Protocol (HTTP), but one could build an API on top of any other remote protocol. In this article, we will focus on REST APIs which are build leveraging HTTP.
Earlier in this post, we talked about the importance of using the correct natural language to make it easier to use APIs. Verbs and nouns help us implement an intuitive interface. We usually see verbs and nouns in class methods, e.g. MyClass().get_info() or MyClass().set_info(). Sometimes the user of a verb is redundant and using only a noun is enough, e.g. MyClass().objects. Using only nouns is very common when we are defining attributes or a method that do both read and write actions.
HTTP already implements a few very basic verbs, which are called HTTP methods. The main HTTP methods used in REST APIs are GET, POST, PUT and DELETE. These methods are readily available in HTTP mainly because they map directly to Create Read Update and Delete (CRUD) operations. These methods cover most operations applied to different resources. There are other HTTP methods: HEAD, CONNECT, OPTIONS, TRACE, and PATCH. From these last methods HEAD and PATCH are used in REST APIs and the rest, while useful, are not usually implemented in REST APIs. You can read more about these methods in the [MDN web docs] (https://developer.mozilla.org/en-US/docs/Web/HTTP/Methods). We will dive into how to use these HTTP methods in the next section.
Since HTTP already gives us a definition of verbs (methods) we can use, it is up to us to figure out the nouns we are going to use. Nouns in REST APIs are directly related to different resources, and they come into play when constructing an API's Uniform Resource Locator (URLs). URLs are HTTP's entry point, when we visit a site we type in a URL in a browser's search bar. In the same way, we can define URLs to access our REST APIs. This is where nouns come into play. It is best illustrated with an example.
Say we are creating an API no manage client's information. Right away we have a noun that makes sense in this context client. This already gives us the correct natural language to use in our URL, and we can define it as https://my-domain.com/api/v1/clients. Let's analyze this URL to understand how it can be used, and we will dive into the details about building a REST API in the next section. We will divide the URL into different sections:

1. The protocol
We talked about how HTTP is the protocol used but, in this URL, we can see the protocol is https. The extra s means Secure. This tells us the communication between a client and this URL is secure.
2. Hostname
This section is where we can find the hostname which will get resolved to an [IP address](https://en.wikipedia.org/wiki/IP_address) that points to our server. This is how packages get routed using the [TCP/IP protocol] (https://en.wikipedia.org/wiki/Internet_protocol_suite).
3. Top level resource
There really is no enforced structure when defining public URLs to access our REST APIs. It is usually a good idea to define a top-level resource name to clearly express that anything containing api/ in the URL means the client will access a REST API.
4. API version
It is a good practice to add a version number to REST APIs. This allows you to roll out changes that might break backward compatibility (if needed) and still maintain past versions of the API. Users are then able to take their time to move into the new version without having everything break if they don't have time to make the necessary changes.
5. Main resource name
In this case, this URL points to our clients resource. It is worth pointing out that resource names are, usually, plural nouns. Using plural nouns make it easier to define actions that will work on multiple objects.
An HTTP request needs a URL and, depending on the HTTP method used, there can also be query string parameters or a body. These are different ways to pass extra data to an endpoint. **Query string** is used on read methods, e.g. GET. We can recognize these values because they are appended at the end of the URL after a ? character. E.g. https://my-domain/api/v1/clients?id=cli-123. A body payload can be passed on an HTTP request when the method used will do some kind of update or creation. The data sent on the body is more secure and safer to use. This data cannot be read by looking at the URL and it can only be retrieved by inspecting the request packet.
Building APIs
We have talked about the different places where we can see APIs in action. In some cases, an API is defined by how we construct classes and functions, in some other cases, APIs are defined by how we construct a URL. Either way, an API should always bring a layer of abstraction which should be easy to use and understand. This abstraction represents the contract that another developer must adhere to when using other developer's libraries, packages, frameworks, REST APIs, etc.
A standardized, simple and easy to follow contract is imperative when building applications, specifically applications like science gateways. Given the fact that gateways tend to centralize functionality belonging to different contexts, these APIs allow different teams to easily use each other’s services or libraries. We can also leverage APIs to easily write documentation and improve readability since natural language is used to build APIs. We must also remember that more in-depth and architectural documentation are great additions to any project as well as automated testing. All of these ideas allow for a project that is easily maintainable, scalable, and understandable.
With building APIs, there is not a single path to take. It depends on how an API will get used, how it will be implemented, and in which context it is going to work amongst other decisions. We can certainly define good practices and aspects to take into consideration when building APIs. Some of these recommendations will be more specific to REST APIs.
Human Readable Specification
Any application must start with a problem to solve and that problem is easily described as a set of specifications. Writing a human readable specification might take some time and the involvement of multiple teams. This specification allows us to identify the details of the problem and correct natural language to use when building our APIs. A short example of our users API:
- Users management service can create and modify users.
- Users have different resources assigned to them.
- Resources can be files, metadata, etc.
- Users can add/modify/delete any resources owned by them.
- Users can search any resources owned by them using a query string.
Identify Nouns to Create Resource's Names
The previous example is a short specification, but we can already start identifying key components. We have shown key verbs and nouns in bold for easier identification.
Nouns:
- Users
- Resources
- Files
- Configuration Details
- Query String
It's always a good idea to use these nouns throughout the entirety of the application. Here we will talk about how to use these nouns on REST endpoints (URLs) but they can also be used to name classes or database tables, to name a few examples.
We might use some of these nouns explicitly in our code and endpoints and some others we might use in documentation. For instance, resource is a keyword used to refer to things like files and metadata. If we use resource as our endpoint name, it might introduce another level of difficulty for whoever is using the API. It becomes more difficult because it will not be explicitly clear what type of resource is an action being applied to. Instead of using resource as the endpoint name we can create multiple endpoints with the actual resource's name. The API will have as many endpoints as unique resource's names. We would still use the word resource in our documentation and even in some of our classes to refer to any common functionality amongst all resources.
Let's show an example of the endpoints we will implement:
- /api/v1/users Users management
- /api/v1/files Files management for users
- /api/v1/files?q=<query_string> Files search
- /api/v1/meta Configuration management for users
- /api/v1/meta?q=<query_string> Configuration search
Identify Verbs to Define Endpoint's Functionality
Verbs:
- Create
- Modify
- Delete
- Search
After identifying the correct verbs we can start mapping them to the corresponding HTTP methods. For this, we need to explain more in detail what each of the HTTP methods that we will be using mean:
- GET: Used for read actions, e.g. Retrieving a list of users
- POST: Write operation. Mostly used to create objects in the server. The most important part of this interaction is that it provides data to the server. While the data sent is mostly used to create a new object of the specified resource it can also be used to create a password reset link, or a short-lived object.
- PUT: Write operation. This method can be used like POST but they differ in a very important aspect. With PUT we essentially place the data sent to the server in the specified URL. It can be used to create an object as well as to replace already existing objects. Replacing already existing objects is used mainly as a way to update these objects.
- PATCH: Write operation. Used to make partial modifications to a resource in the server. PATCH can be viewed also as a way to update a resource which could also be achieved with PUT. The difference between these two methods is that PUT replaces the entirety of an object in the server while PATCH makes a more granular modification to a resource, e.g. modify the last name of a user.
- DELETE: Delete operation. Used to delete a specified resource in the server.
After analyzing the correct use of these HTTP methods we can map our verbs to the correct HTTP method:
- GET:
- Get user details
- Search resources
- POST:
- Create users
- Create resources
- PUT:
- Modify Users
- Modify resources
- PATCH:
- Make specific modifications to users
- Make specific modifications to resources
- DELETE:
- Delete users
- Delete resources
API Specification
With a human readable specification, we have identified the key nouns and verbs we need to use in our API. After identifying these nouns and verbs, constructing the different endpoints and the architecture behind the different HTTP methods becomes easier.
We have already identified the endpoints we need when we identified the key nouns. Sometimes these endpoints can change depending on the verbs identified. These modifications come in place when an important verb in the human readable specification needs to act as a noun. The idea of a verb becoming a noun might not be clear from the beginning but it usually simplifies the use and implementation of an API. For instance, if our main specification asks for a user to be able to publish files. It is not clear how to map a verb like publish to an HTTP method. Instead, we can create a new type of resource which will be named by the noun behind the verb publish. The new resource name can be publications. This makes the API implementation easier because now we have isolated what essentially is a relation of objects. A publication can be defined as a file and a public link. This is all the information a publication will hold (in practice a publication will be more complex). After defining our resource name we can now add to our API specification that users can create (POST), modify (PUT, PATCH), delete (DELETE) or list (GET) a publication.
Let's take a look at how some of these endpoints will look in practice. This will define the specification of how our API will work. This specification should be thoroughly documented. We will use the command line tool curl which is a simple tool that allows us to make HTTP requests through the command line.
The basic curl syntax we'll be using looks like this:
1. curl is the command line tool we'll be using.
2. -X specifies which HTTP method we'll be using.
3. The complete URL to make the request to.
4. -d is only used when we need to send data in the body of the request. This is for POST, PUT and PATCH verbs.
List Users
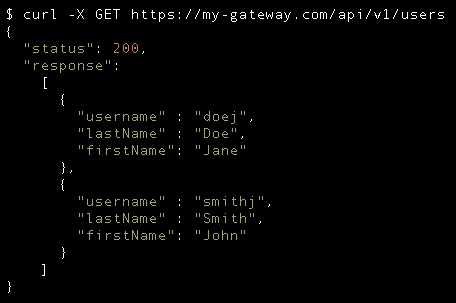
Note: Listing users might be an endpoint reserved for admin users.
Create Resource
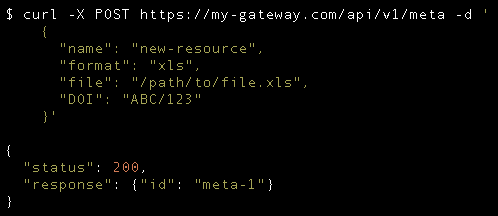
In this example, we can see how we're sending all the necessary details for a metadata record to be created. This metadata record will be pointing to a file path. In the response, we can see there is an id that we get back from the server. This is usually necessary since POST will only send the resource's details, the user will then assign a unique ID to the created resource.
Modify Resource
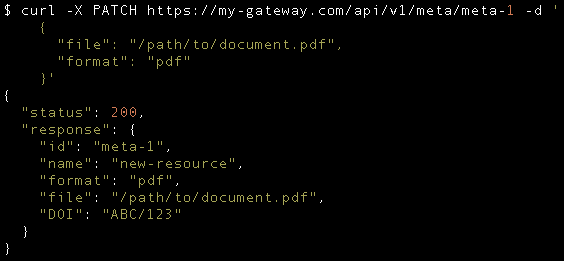
Here we are updating a metadata record to link it to a different file. The response is different from when we created the same resource. This is mainly to show that we can respond with a different representation of the same resource. The best practice here is to always use the same type of representation when responding to the same HTTP method. We can choose any representation that seems fit for the endpoint use.
Delete Resource

We can notice that when we are doing something to a specific resource we are using the resource id in the URL. In this case meta-1. This makes it clear that the action we want the server to apply is to that specific resource. Readability counts.
Overwrite a Resource
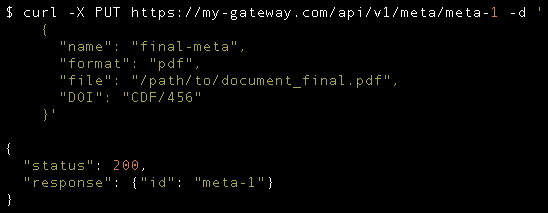
It is not necessary to implement every HTTP method for every resource. We should always implement what makes sense from the requirements. In this case, we are allowing a user to update and also to completely overwrite a metadata record. There might not be a need to implement these two functionalities if PATCH can also be used to update every field in the record. Now, we might still want to implement PUT since maybe we can allow a user to specify the unique id for a metadata record. This can complicate things in the implementation since we need to take into consideration that we must validate for the custom id to be unique. We can see how elastic REST APIs can be and how we must be careful to decide how each endpoint will behave.
Documentation
A big part of an API must be the documentation. In gateways, most of the public APIs will be used by users to implement custom automated workflows. A well-written documentation should make an API's usage a breeze. Writing documentation is not always a simple task and it should be considered part of the development process.
Recommendations when writing documentation:
- Overall architecture documents help users understand design decisions
- Explain design decisions, it makes it easier on the user to use your API if they understand why it was implemented the way it was.
- Add examples on how to use your API.
- Document the standards used, how each resource is named and represented, as well as how responses behave.
- Documentation is written by multiple teams.