Tech Blog: How the Ocean Observatories Initiative Used Apache Kafka to Simultaneously Combine Large Volumes of Historic and Streaming Data
- Details
- Published on Monday, 11 November 2019 14:00
By Choonhan Youn
What is Apache Kafka?
Apache Kafka is a distributed messaging system, which publishes and subscribes to streams of records, similar to a message queue or enterprise messaging system. It is developed to be a distributed, partitioned, replicated service. Ocean Observatories Initiative (OOI)’s data streaming-based science gateway uses this message brokering system. To balance the incoming load, Topics are defined and each of these Topics is split into multiple partitions, each storing one or more of those partitions with the ability to accept multiple formats, varying from text, image, video, and other formats.
Kafka is suitable for building real-time streaming data pipelines that reliably pass data to systems or applications by running on a cluster of servers. The Kafka cluster stores and categorizes streams of records in Topics, while these records consist of key, value, and timestamp.
Kafka has two main APIs as follows:
o The Producer API allows an application to publish a stream of records to one or more Kafka Topics.
o The Consumer API allows an application to subscribe to one or more Topics and process the stream of records produced to them.
Figure 1 (see below) shows the role of each of these. Topics are the core abstraction which Kafka provides for a stream of records. A Topic is a category or feed name to which records are published. Topics are also multi-subscriber and may have zero, one, or many consumers who may access the data written to it.
The Kafka cluster always retains all published records, without consideration of their consumption. Producers publish data to the desired Topics; it chooses which record to assign to which partition in the Topic; this may help with the load balancing. Each record published to a Topic is accessed by one consumer, where it may be in separate processes or on separate machines.
Within OOI, we leverage data infrastructure building blocks such as the Virtual Data Collaboratory (VDC) that provides data and computing capabilities in the continuum to efficiently and collaboratively integrate multiple data-centric cyberinfrastructure, build data-driven workflows, and connect large facilities data sources with NSF-funded cyberinfrastructure. The dashboard application which is deployed at VDC is composed of three main components: (i) the science gateway, (ii) the scientific workflow system, and (iii) a graphical user interface. The science gateway is deployed with a set of agents that retrieve data from the observatory and publish them to the message broker system using Kafka Topics. The scientific workflow system is subscribed to the Kafka Topics and continuously produces the data products (e.g., plots for different parameters) based on the configuration parameters such as the plot granularity and plotting frequency. When new plots are generated they are automatically serialized and published to the message broker system using Kafka Topics associated with these products. These Kafka Topics and the Kafka Topics with the data pulled from the observatory are all available for users to subscribe to them.
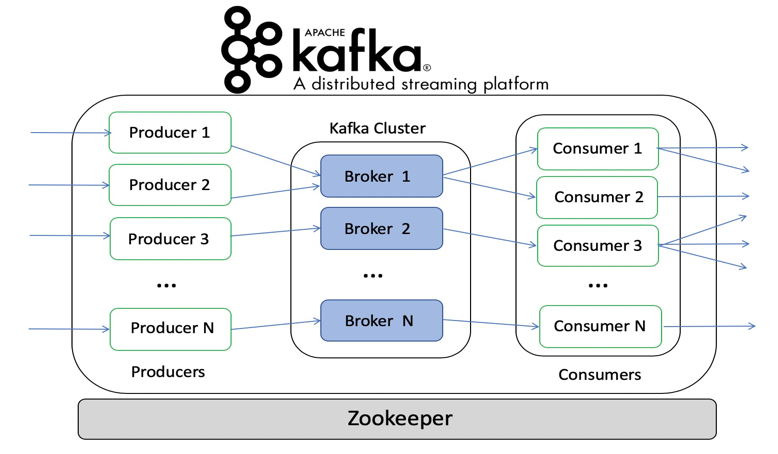
Figure 1. A high-level architecture of Apache Kafka for large-scale data processing service.
What are the benefits to science gateway developers? What problems does it address?
The NSF Ocean Observatories Initiative (OOI, https://oceanobservatories.org/) implements a geographically distributed, secure, highly available cyber-infrastructure that is responsible for data acquisition and collection, data storage and processing, and on-demand delivery of data and data products to scientists and application developers.
There are two main data delivery challenges. The main data delivery in OOI is based on an on-demand product generation in the form of synchronous pull-based data requests or asynchronous download of NetCDF data sets. As a result, current data delivery methods are not optimal for real-time processing, quality control/evaluation, event detection, and distribution of this high sample rate data. Next, the science community has developed community tools using the OOI M2M (Machine To Machine) API for providing users with means to access data in “real-time”. These tools employ the OOI API to continuously make requests for new data, even if the data is not available in the system, which ends in a large number of failed requests. As a result, these tools require hundreds of thousands of pull-based data requests to be served daily per user, which is not a sustainable approach.
This science gateway addresses this problem by leveraging the OOI API for developing a scalable, reliable, sustainable, subscription-based mechanism for real-time streaming-based data delivery to users.
How can it/has it been implemented by SGCI staff?
The prototype implements the resource broker based on Apache Kafka illustrated in Figure 2 (see below), which delivers data streams from the OOI cabled array in near real-time and provides a Java-based interface.
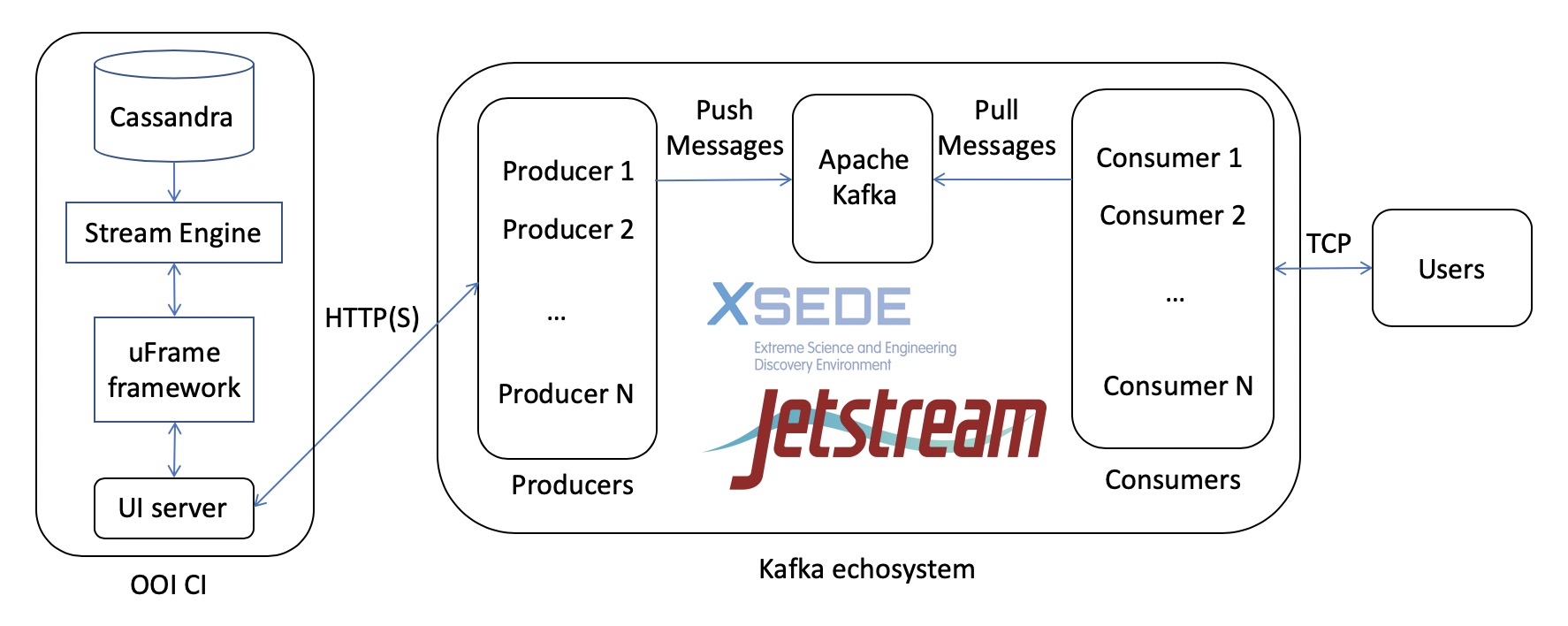
Figure 2. A resource broker system architecture: push-based on-demand OOI data delivery through Cyberinfrastructure.
In our implementation, this architecture has three functions, consisting of Kafka producer, Kafka consumer, and Topic manager. To increase the efficiency in the application development process, we designed and implemented a JSON schema that defines the information necessary to specify scientific instruments in a message broker and to perform the data streaming process through these three functions in a straightforward way. It contains multiple instruments of metadata such as the name and code of array, platform, instrument, mooring and stream type, and method. The Kafka producer and consumer are used for publishing/subscribing to the targeted sensor instrument for multiple streams. The Topic manager shows the number of instruments registered and can create/remove the targeted Topic in a message broker to a particular instrument. Further, easy-to-use front-end tools enable the end-user to be able to subscribe to OOI data and make data delivery and format choices.
What would make someone choose this solution over another?
Due to the fast growth of sensor networks around the earth, the amount of generated data in these networks is increasing exponentially. Dealing with the environmental data, which are arriving in a large volume in every second, needs a proper framework which does not rely upon storing data on the storage, and can process data in memory, as it arrives.
In this framework, data processing workflow usually connects computing resources to automate a sequence of tasks (e.g., event streams) by processing large volumes of data, where different resources are connected for automating different tasks. In the case of streaming data processing, Apache Kafka, which is used for a scalable and distributed platform, is required for combining large volumes of historic and streaming data at the same time.
Steps of implementation
Like the prototype, using Java, we implemented software agents to automatically pull data from OOI via M2M REST API and insert it to the message broker system.
Implementation steps are as follows:
-
Install and deploy Apache Kafka into XSEDE Jetstream. Three nodes in this cluster were configured. Please see the quick start guide, https://kafka.apache.org/quickstart.
-
For managing Topics, design the JSON schema that contains the metadata of sensor instruments, and implement the Topic manager to The Topic manager which shows Topic names associated with instruments and can create/remove the targeted Topic in a message broker to a particular instrument.
-
Implement a Kafka producer, which is pulling data from OOI M2M API and publishing these data into data streams, that is, targeted Topics.
-
Implement a Kafka consumer that allows multiple users to subscribe to data streams (targeted Topics) through a scalable broker system, in order to process each record published to a Topic.