Guest Tech Blog: Kubernetes and JupyterHub on Jetstream
- Details
- Published on Wednesday, 17 March 2021 20:00
By Andrea Zonca, HPC Applications Specialist, San Diego Supercomputer Center
Introduction
JupyterHub handles authentication and routing for any number of users that have access to an interactive computational environment, the Jupyter Notebook, via their browser.
The most high-impact application of JupyterHub in the context of Science Gateways is to deploy it as a companion application for the Science Gateway to enable users to access a pre-configured computing environment. This configuration allows them to use the Gateway programmatically and apply custom processing of the gateway input or outputs. For example, the Gateway users could use the same login credentials to also access a Jupyter Notebook environment with tutorial notebooks displaying example analysis pipelines that show how they can:
-
upload raw data
-
use packages installed in the Jupyter Notebook environment to pre-process raw data to transform them in the format suitable for the Science Gateway
-
submit the data for processing using remote execution APIs
-
check the job processing status
-
retrieve the results
-
load the output data from disk
-
post-process and plot the results
Let's proceed now to show an overview on how to deploy first Kubernetes and then JupyterHub on Jetstream.
Jetstream
Jetstream (and the upcoming Jetstream 2) is a cloud deployment part of XSEDE, the science community’s equivalent of Amazon Elastic Compute Cloud (EC2) or Google Cloud Platform. Many Science Gateways already run on Jetstream.
Jetstream allows each user to programmatically launch Virtual Machines with the desired amount of CPU/RAM resources, a pre-configured OS (Ubuntu, CentOS...), connect them together on an internal network and expose them to the Internet with public IPs. Users have then full administrative access to the machines to install any software package.
Jetstream has extensive documentation and training available both focused on using the simplified Atmosphere interface and the programmatic access via web API. Once developers decide to try Jetstream, they can request a trial or a startup allocation via XSEDE.
Deployment on Jetstream should begin with gateway developers identifying the scale of their deployment: few-user or test deployment vs. large-memory, many-user deployment.
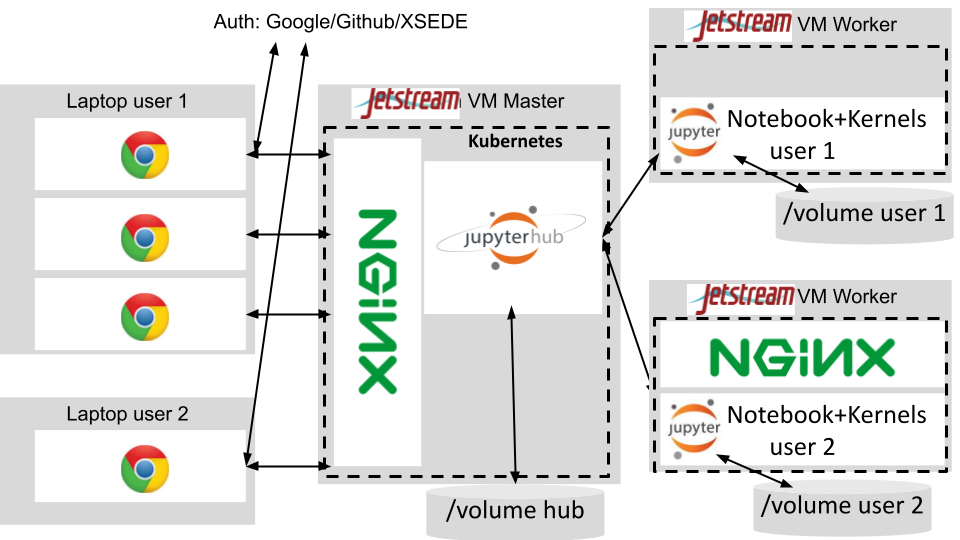
Architecture of the deployment of JupyterHub on Jetstream: the users connect via their browser to the Jetstream master node virtual machine, they first are redirected to external services for authentication. Once authenticated, JupyterHub spawns a container running the Jupyter Notebook for them in one of the worker nodes managed by Kubernetes. Their own persistent data volume is also mounted there. Kubernetes handles the networking so that the interactive computing session is proxied back to the users' browser.
Single server deployment
In the case of a test deployment with a small number of users, each with limited computational resources, we can avoid the complications of a distributed deployment.
The most important requirement is memory, a reasonable estimate is to have available 128 MB of RAM for JupyterHub services and then multiply the number of concurrent users by the memory we want to allocate for each user. For example, if we give each user 10 GB of RAM, we could host 11 concurrent users on a Jetstream XXL instance with 128 GB of RAM and have significant margin for system services.
In this case, we can just spawn a single, large-memory Virtual Machine on Jetstream and then follow the "Littlest JupyterHub" documentation to install JupyterHub.
Kubernetes
However, if the sum of the memory needed by all the users is higher than 120GB, we need to deploy JupyterHub across multiple Jetstream Virtual Machines. The recommended way of deploying a distributed instance of JupyterHub is on top of Kubernetes, which is able to provide networking, logging, reliability, and scalability.
I have configured and adapted the Kubespray tool to deploy Kubernetes to Jetstream and have written a step-by-step tutorial about it, which includes all the necessary configuration files. A Jetstream user can launch this script to programmatically launch any number of Jetstream instances and deploy Kubernetes across them. Consider also that Kubernetes would be a good platform to deploy a Science Gateway itself, especially if it already has a distributed architecture (for example, the gateway website, a database, and worker processes that execute computations). However, Kubernetes itself is a complex system, which requires someone in the Gateway development team to invest significant effort in learning how to configure and administer it.
After Kubernetes is deployed, we now have a programmatic interface where we can deploy applications packaged as Docker containers, monitor their execution, log their warnings or errors, and scale them based on load.
JupyterHub
Finally, we can leverage the Zero to JupyterHub project and customize their recipe to automatically deploy all the components needed for a distributed JupyterHub deployment on Kubernetes.
We can configure authentication with Github, Google, XSEDE, or CILogon, choose a Docker container with all the packages needed by the users, decide how much RAM, CPU, and disk each user has access to, configure a public URL, and setup HTTPS.
Once the deployment is complete, the users can point their browser to the master node of the deployment, authenticate and have a Jupyter Notebook be spawned for them across the cluster of Jetstream instances with a dedicated amount of computing resources.
We can also pre-populate the computational environment with tutorial notebooks that display example data analysis pipelines that jointly leverage JupyterHub and the Science Gateway. A few hours after a user disconnects, their container is decommissioned to free up resources for other users, but their data is saved as a permanent disk on Jetstream and is mounted again the next time they reconnect.
Conclusion
This is a basic overview of the different components involved in deploying a distributed instance of JupyterHub on Jetstream. To know more, check out the list of references below. If you have any feedback or would like to collaborate, please open an issue in my jupyterhub-deploy-kubernetes-jetstream repository.
References
-
Video tutorial on Openstack and Kubernetes for the ECSS Symposium
-
Tutorial on how to deploy Kubernetes and JupyterHub on Jetstream via Kubespray
-
Tutorial on how to setup SSL for HTTPS connection to JupyterHub